互联网热点搜索与追踪的研究和实现
张维楚 高 翔
(国家新闻出版广电总局厦门监测台 厦门 361009)
摘 要 本文重点阐述互联网热点搜索与追踪的实现技术,采用基于网站信息模块快速定位的网络爬虫方法搜索和追踪网络热点事件,同时根据数据挖掘理论中的字符串相似度的匹配方法计算网络事件热度值,统计分析搜索数据,提高互联网热点搜索与追踪的工作效率,为互联网的监管工作和决策提供素材,提高了互联网监管的工作效率和决策水平。关键词 互联网,发现和汇聚,搜索,相似度0 引言
随着互联网的高速发展,截至2014年12月底,我国网民规模达到6.49亿,互联网的普及率为47.9%,中国“.CN”域名总数为1109万,年增长2.4%,占中国域名总数比例为53.8%;“.COM”域名数量为795万,占比为38.6%;“.中国”域名总数达到28.5万。网民和网站的数量逐年上升,互联网日渐成为社会信息的集散地,是社会舆论的放大器,很多言论通过互联网放大、推进、炒作,并形成舆论,占据第一影响力媒体位置。互联网逐渐成为热点舆论的发酵平台,对人们生活的影响与日俱增。互联网给人们的生活提供了很多便利,同时网络舆论引发或推动的大量热点事件层出不穷,互联网“双刃剑”的作用也不断显露,80%的政府和企业危机来自于互联网。如果对互联网的热点舆情掌握不及时、处置不恰当,可能对社会稳定、政府形象等多个方面带来严重影响,因此,互联网热点的搜索和追踪成为政府企业必需要重视的工作,时刻掌握社会舆论的动态,提高政府服务的工作效率和决策水平。传统的人工收集和统计的方法已经远远不能满足互联网海量信息的需求,本文基于日常工作需要,提出了基于相似度的互联网热点搜索与追踪方法,并应用C#开发热点搜索与追踪应用软件,采用软件辅助,大大提高了互联网热点搜索与追踪的工作效率。1基于模块定位的爬虫算法
网络爬虫是一种按照一定的规则,自动抓取万维网信息的程序或者脚本。它是一个自动提取网页后台内容的程序,从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便查询和检索;对于爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。目前网络爬虫常用的有广度优先搜索策略,最佳优先搜索策略,深度优先搜索策略,在搜索的过程中又同时结合运用选择策略、重新访问策略、平衡礼貌策、并行策略等。巨大的网络数据量使得爬虫在给定的时间内,只可以抓取所下载网络的一部分本文,而且所获得的信息可能很多都不是所需要的。为了提高爬虫在搜索与追踪的速度和针对性,本文采用了基于模块定位的网络爬虫方法,首先根据各个网站的模块设计,采用字符匹配的方式定位到所要的热点事件的模块,然后根据正则表达式使用单个字符串或者多个字符串来描述、匹配一系列符合某个句法规则的字符串,从而搜索和追踪热点新闻事件,大大缩短搜索周期,提高搜索效率。2 相似度算法
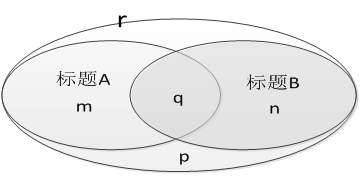
在数据挖掘理论的研究中,经常会遇到如何确定两个字符串之间的相似程度的问题。本文根据数据挖掘理论的相关方法以及字符串的特性,采用二元变量的方法对互联网新闻标题进行分析,利用分词技术将字符串分成若干个单词(字),每个独立的单词(字)作为二元变量的一个属性,相互比较的两个标题字符串A和B的所有单词(字)为一个二元变量属性集合r,标题A和B的单词包含于集合r,它们的相互关系如图1所示:图1 标题A和B相互关系图
上图中q为标题A和B共有的单词数目,m是标题A有而标题B没有的单词数,n是标题B有而标题A没有的单词数,p是标题A和B都没有的单词数。在本文中,不存在标题A和B以外的单词,所以忽略p,即p=0。于是采用非恒定的相似度评价系数推断出它们之间的相似度公式为:。考虑到实际应用中新闻标题一般不会出现重复的单词,本文在研究中不考虑单词重复出现的情况。同时,在实际的应用中,q、m、n三个分量往往具有不同的价值(我们称为影响因子),比如相同单词的数量更加能说明两个标题的相似度。本文分别给三个变量赋予不同权重,应用到上面的公式得到:相似度=其中,、、分别为q、m、n三个变量的影响因子值。在众多网站的海量搜索结果中采用相似度算法可以判断出两条不同新闻的相关性,从而找出当前“热点”。3 互联网热点搜索与追踪方法的设计实现
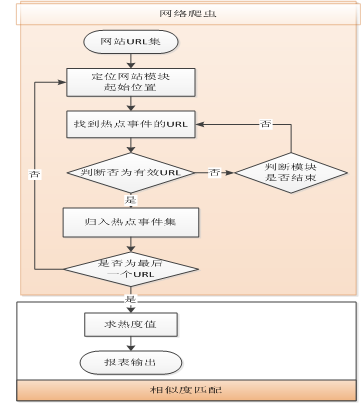
在互联网热点搜索与追踪过程中,本文采用网络爬虫算法,针对境内外主流网站的热点新闻模块进行数据挖掘,搜索所要关注模块的热点新闻标题。然后根据字符串相似度的算法,对网络爬虫搜索到的每个新闻标题进行两两相似度的计算,当某个新闻标题与另外一个标题的相似度大于或者等于0.5的时候,该新闻的热点值加1,从而得出该新闻的全网络热度值,实现流程如图2所示。图2 热点搜索与追踪流程图
在本文的应用中考虑到相同词的数量对相似度的影响比较大,所以q、m、n的影响因子的取值分别为2、1、1。以标题A“张三登陆欧洲”和标题B“张三抵达欧洲”为例,它们的关系属性如下表所示:表1 关系属性表
| 标题\属性 | 张三 | 登陆 | 欧洲 | 抵达 |
| 张三登陆欧洲 | Y | Y | Y | N |
| 张三抵达欧洲 | Y | N | Y | Y |
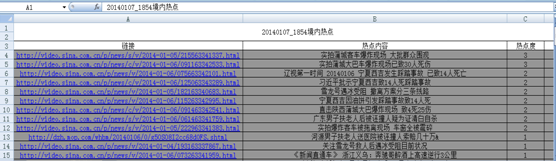
图4 境内媒体热点事件月报表
另外,本软件可以对互联网进行日常检查,对特定时期进行阶段检查,如国庆等重要保证期,还可以针对特定事件做追踪搜索分析等等。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
评论 点击评论