面向全样本用户的收视特征提取算法与优化
张 帆 陈 征 颜金尧
(中国传媒大学计算机与网络中心)
摘 要:数字电视机顶盒可收集到电视用户的频道收视行为数据。而通过采集的收视数据提取用户收视特征,贴上对应标签,可提高电视广告精准化投放所需的基础信息。当收视行为数据为全样本用户时,需要提取收视特征的高速处理算法。本文首先提出了对用户收视特征提取的初始算法,可用于在小样本环境下验证与改善数据分析流程。然后在初始算法上进行基于数据读取方式、数据类型、数据表结构三方面的优化,提升后的数据处理效率约为初始算法的17倍。新的高效数据预处理算法能够快速的实现收视特征提取,为全样本环境下的用户标签分析奠定基础,有效缩短了数据挖掘过程的迭代周期。关键词:收视特征提取 算法优化 数字电视 数据预处理 Python1 引言
受网页广告精准化快速发展的驱动,对电视广告效果进行进一步量化考核的需求也在日益提升。而广告精准化投放的关键是为每个用户贴上相应的标签[1],更准确的将用户与潜在广告投放需求关联。为了在电视用户收视行为分析中更准确的为用户贴上标签,可采用的主要数据特征之一是用户的收视特征,包括用户曾观看的节目与广告信息等。双向数字电视从技术层面上改变了原有少量样本户方式调查的测量方法,全样本分析成为收视分析的新架构模式。2014年8月视广通与尼尔森网联发布的用户报告[3]指出,在29天的数据统计中采集的电视用户行为数据为8亿条以上。全样本的海量数据采集为用户收视行为的大数据分析奠定了基础,但全样本数据带来的处理压力,促使在提取收视特征的数据处理阶段需要更为高效的数据预处理算法。数据预处理所占的工作量通常达到了整个数据挖掘过程工作量的60%至80%[4]。为了快速实现算法逻辑,在小样本环境下验证分析流程,我们首先提出了一种简要的初始算法,可以完成收视特征的统计与分析。但是初始算法的效率不足以支撑全样本环境下海量用户的快速分析。因此,我们在初始算法上提出了基于数据读取方式、数据类型、数据表结构三方面的算法优化方案,以提升算法的执行效率。本文共分为三部分内容。第一部分介绍了收视特征提取流程以及我们所采用的初始算法;第二部分提出基于数据读取方式、数据类型、数据表结构三方面的算法优化策略;第三部分是对算法优化效果的实验分析与评估。2 收视特征提取流程与初始算法
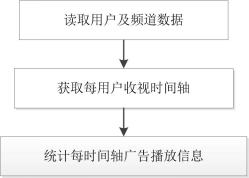
收视特征提取将依据收看记录统计用户曾观看的频道与广告信息,其提取流程包括读取用户及频道数据、获取每用户收视时间轴、统计每时间轴广告播放信息三个步骤,如图1所示。图1 收视特征提取流程图
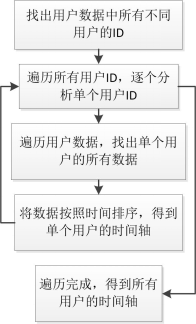
依据收视特征提取的流程,我们提出了实现特征提取的初始算法。其详细算法设计如下:(1)获取每用户收视时间轴:先通过分析用户观看记录获取每个用户观看电视的时间轴,然后通过分析时间轴,得到用户观看电视的详细信息。用户观看记录包括三个部分:用户标识(后文用“用户ID”表示),观看频道标识(后文用“频道ID”表示),观看起始时间。首先需要找出数据集中所有不同用户的ID,再根据某个用户ID找出此ID的所有记录,并对记录进行以观看起始时间为基准的排序,整理出用户收视时间轴。获取每用户收视时间轴的流程如图2所示。图2 寻找用户时间轴流程图
以时间轴上某点为基准,将此点的时间作为用户观看起始时间,将其下个点的时间作为用户观看结束时间,再加上此点的频道ID,便组成此点完整的观看信息。图3是具体分析某一用户观看时间轴的结果样例。图3 用户观看时间轴
(2)统计每时间轴中的广告播放信息。广告的时间信息包括四个部分:频道标识(用来标记不同频道,与用户观看记录中的频道标识相对应,后文亦用“频道ID”表示),广告种类,广告起始时间,广告结束时间。通过频道ID的映射,将用户观看时间与广告时间作对比,当用户观看起始时间小于广告起始时间,且广告结束时间大于用户观看结束时间,则判定此条广告在用户终端上进行了完整播放,并将此条广告的种类与用户ID绑定记录。处理完所有数据会获取到不同用户观看不同广告种类的次数。由于不同广告种类的播放次数不同,为了对用户贴上合适的标签,收拾特征提取完成后还需要分析广告种类的播放次数与用户观看次数的内在联系。3 算法优化设计
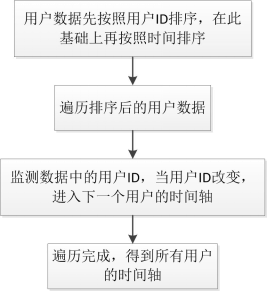
初始算法可以完成收视特征的统计与分析,在小样本环境下验证与改进数据分析流程。但初始算法在全样本环境下分析用户行为时,还存在可优化空间。因此,我们在初始算法上提出了基于数据读取方式、数据类型、数据表结构三方面的算法优化策略,以提升算法的执行效率。3.1 数据读取方式优化初始算法的数据读取方式采用了频繁调用数据库的方式,每分析一个用户便调用一次数据库以获取每用户的时间轴。分析发现,用户ID都是整数,如果把所有数据按照ID进行排序,相同ID的数据会被排在一起。优化后算法的数据读取方式修改为对数据进行基于时间的排序(即相同ID的数据再进行时间排序),便能获取每用户的时间轴,调用一次数据库即可以完成对所有用户的分析。假设有Ld条用户数据,由Li个用户的数据组成,初始算法中分析这些用户数据需调用Li次数据库,每次调用需Ld次数据读取。将一次调用数据库的时间记为Tcall,一次读取数据的时间记为Tread,则分析这些用户数据所需读取时间为Tr: 数据量Ld会随着用户个数Li的增大而增大,说明初始算法的时间复杂度为O(nZ),运行时间会随着数据量的增大成抛物线形式增长。进行数据读取方式优化后,将排序时间记为Tsort,此时读取时间为Tr: 在Tr中,数据排序时间Tsort小幅度增加,但整体数据读取时间大幅度降低。可以看到,将数据读取方式优化后算法的时间复杂度与Tsort的时间复杂度相同。当采用基数排序算法后,时间复杂度为O(zN),随着数据量的不断增大,算法的运行时间呈线性方式增长,优化效果随数据量的增大越加明显。此时获取每用户收视时间轴的流程如图4所示。图4 优化数据读取方式后寻找用户时间轴流程图
3. 2 数据类型优化初始算法的数据类型采用解释型语言的对象类型(datetime)。然而解释型语言的对象类型在数据运算方面效率过低。优化后算法的数据类型采用了运算效率更高的整数类型(int),可提高算法的执行效率。相对于编译型语言,解释型语言具有编写效率高、跨平台性好等优点。由于注重开发速度,解释型语言中包含很多内置模块,通过提供调用接口,让开发者更加高效的进行功能的开发而不是耗时在细节函数的实现。例如,解释型语言会包含专门用以处理时间的模块,模块中含有时间类以定义时间对象,便于对时间对象进行比较、加减等运算。被时间类定义的时间对象的类型被称为时间类型。时间类分为三步完成对象的运算操作。首先,时间类型对象先被转换成为整数类型的时间戳,然后对时间戳进行运算。最后,当运算结束后,将整数类型的结果转换回时间类型。初始算法存在大量时间比较操作,并不需要返回时间类型的对象,时间类的最后一步操作可以省略。基于此,我们放弃便于操作的时间类型,当录入时间数据的时候,直接将需要进行比较的对象转换成为整数类型的数据,通过直接比较整数类型数据来分析时间数据,省去了将整数类型数据转换为时间类型数据的时间,提升了算法的运行效率。3.3 数据表结构的优化为统计用户观看频道的信息,需要在指定的频道信息表中遍历。初始算法的数据表结构将所有频道数据都存储在单一表结构中。优化后算法的数据表结构将频道数据按频道ID拆分为若干个数据表,每个数据表仅存储单个频道的数据,提高了检索效率。广告数据包括四个部分:频道ID,广告种类,广告起始时间,广告结束时间。初始算法中广告数据被存入一个数据表,当用到指定频道的数据时,需遍历整个数据表,找出指定频道ID的数据。由于广告数据信息的数量较大,遍历数据表会消耗很多时间。优化后算法在录入广告数据时,以不同频道ID为表名,将不同频道的广告数据存入不同的数据表中。当用到指定频道的数据时,查找以此频道ID命名的数据表即可。这样会增加物理内存占用量及建表时间,但是可以省掉很多运算时间。4 实验结果及结果分析
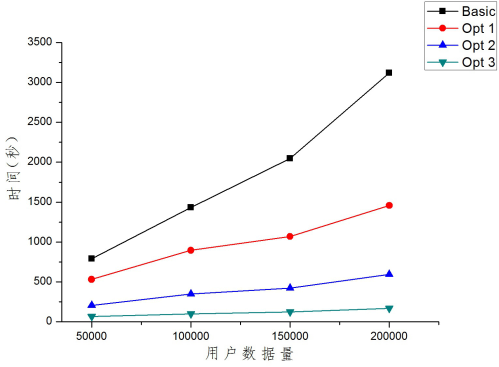
为评估用户收视特性提取算法的优化效果,我们在同一实验数据集基础上对三种算法的运行时间进行记录,通过比较算法运行时间评估三种方案的优化效率。本文中实验使用单台PC工作站完成,工作站配置如下:处理器:Inter(R) Core(TM)2 Duo Cpu E7200 @2.53GHz 2.53GHz;内存:4.00GB(3.25GB可用);系统类型:32位WIN7操作系统。实验程序的编程语言为Python[7],是一种面向对象、解释型计算机程序设计语言,具有良好的跨平台性。在2.7版本以后,Python集成了SQLite[8]数据库,方便用户利用Python进行数据库操作。本文中实验均利用SQLite数据库作为持久化存储工具。改变用户数据量,得到不同方法所用时间如图5所示。分析所采用的数据量分别为5万条、10万条、15万条与20万条,其中Basic时间曲线是未经过任何优化的算法,Opt 1时间曲线是在初始算法的基础上优化了数据的读取方式,Opt 2时间曲线是在优化过数据读取方式的基础上进行了数据类型的优化,将Python中的datetime时间类型通过转换直接保存为整数类型的时间戳,Opt 3时间曲线是在前两个优化的基础上又将广告数据的数据表进行了拆分。图5 算法运行时间对比
由实验结果图(图5)可以明显看出,三种算法优化方案均提高了算法的运行效率,三次优化过后,在处理20万条数据时,数据处理速度(处理数据条目/秒)由约60条/秒增长至约1000条/秒,增长了约17倍。进一步分析图5曲线走势,可以看出,当用户数据量逐渐增大时,初始算法的运行时间呈抛物线形式增长,数据处理速度越来越慢,而在优化过数据读取方式后,算法运行时间随着数据量的增大稳定为线性增长,数据处理速度基本稳定。这是由于初始算法的时间复杂度为O(),随着数据量n的增大,处理速度将会降低,而算法的时间复杂度在优化后变为O(),数据处理速度基本保持不变,为分析更多的数据提供保障。视广通与尼尔森网联发布的报告[3]指出,29天中收集7百万台电视终端共计8亿条以上数据,平均1天内每个电视终端产生数据约4条。以此数据量为参考,初始算法在数据量为20万条时处理速度为60条/秒,估算每个小时能处理约5.6万(60*3600/4=560000)台电视终端产生的数据,采用优化后的算法后,数据处理速度提高至1000条/秒,每小时可以处理约90万(1000*3600/4=9000000)台电视终端的数据,提高了约17倍的执行效率。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
评论 点击评论