吴 波
(国家新闻出版广电总局监测数据处理中心)
摘要:随着广电统一监管平台的整合,广播电视节目编目系统需要对全国近千套频道的播出节目进行自动编目。Hadoop作为开源的大数据云平台,可通过扩充其功能实现对海量视音频文件的处理。本文分析了广电统一监管平台下节目编目系统现存的问题,提出了基于Hadoop的存储和计算的优化方案,并给出了数据处理主要步骤的实现方法。
关键词:Hadoop;大数据;视频处理
1 引言
广播电视节目编目系统的建设,是广播电视统一监管平台的重要工作之一。目前广电统一监管平台的节目编目系统利用视频处理技术,根据节目间的可区分特性、节目模板的固定性和可定位特性实现节目的自动编目[1]。随着广播电视内容监管的范围不断增大,广电统一监管平台每天从全国采集近千套节目频道的录像文件,如何实现对海量视频文件的快速处理,是广播电视节目编目系统需要解决的问题。近年来,基于Hadoop的分布式计算平台在大数据处理方面得到了广泛的应用。Hadoop具有吞吐量大、自动容错等优点,可处理PB级别的数据[2]。然而,当前Hadoop多用于处理文字信息[3],在视频中也主要局限于视频转码这一方面[4][5][6]。因此,需要依据广播电视节目编目系统的技术特点,给出合适的解决方案。本文先分析了广播电视节目编目系统现存的问题,随后提出了基于Hadoop的编目系统的优化方案,包括分布式存储和计算的设计方案,以及其中主要步骤的实现方法,最后得出结论。
2 现有系统的架构
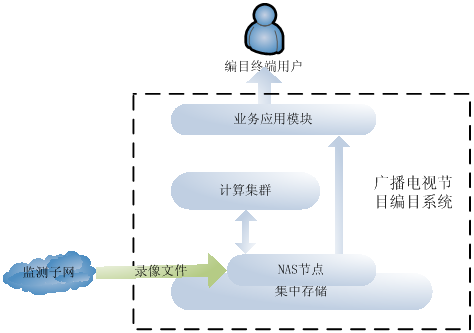
广电统一监管平台现有的广播电视节目编目系统架构如图1所示[1]。
图1:广播电视节目编目系统现有架构
系统处理流程如下:
- 监测子网前端将监测到的录像,以2小时一个文件,写入到集中存储子系统中;
- 计算服务器依据频道划分计算任务,通过网络附加存储(NAS)节点从集中存储中读取录像文件,提取录像文件的关键帧,将关键帧写入到集中存储中;
- 计算服务器读取关键帧,调用相应的算法处理关键帧,将结果写入到集中存储中;
- 业务应用模块读取集中存储的编目结果,提交给用户进行审核。
现有系统存在着以下问题:
- 随着系统计算规模的扩大,大量的计算服务器会从NAS节点频繁读取文件,由于服务器CPU处理速度往往高于文件读取的速度,因此计算集群和存储之间的IO操作,会成为编目系统的性能瓶颈[7];
- 由于监测子网不同前端到集中存储的网络带宽不同,不同频道的文件回传到集中存储的速度有块有慢。采用频道划分计算任务,会导致同一时段,有些服务器过载,而有些服务器空闲,计算资源没有得到充分利用。
Hadoop作为开源的大数据处理平台,其优势体现在[3]:
- Hadoop提供的HDFS文件系统可将数据分布式的存储在各个节点上,计算时各个节点可读取存储在本地的数据,从而避免了大量的数据在网络上的传输;
- Hadoop提供的MapReduce分布式编程模型允许开发人员在不了解分布式计算底层细节的情况下开发程序,降低了开发的难度;
- 为应对服务器失效,Hadoop会将数据块形成多个副本存储在不同节点,可避免数据失效,同时也可让多个服务器同时处理同一块数据,保证计算能可靠的执行;
- 虽然Hadoop只提供了处理文本文件、数据库、以<key, value>格式存储的二进制文件的操作接口,但是由于Hadoop是开源系统,因此可以针对编目系统视频文件的特点,方便的进行功能扩充。
3 基于Hadoop的系统设计
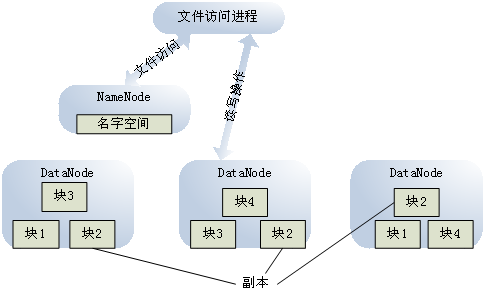
3.1 基于HDFS的存储设计系统利用Hadoop的HDFS分布式文件系统存储数据。由于编目系统处理的是录像文件的关键帧,因此可以在HDFS文件系统中直接存储关键帧文件。存储结构如图2所示。
图2:存储结构
HDFS包含两种节点:NameNode和DataNode。其中,NameNode负责维护文件系统的名字空间,并响应对文件系统的访问。DataNode存储实际的关键帧数据,并向NameNode发送心跳信息。文件进入到HDFS文件系统中时,会被分割为固定大小的数据块,保存在不同的DataNode上,每一个数据块默认为3个副本。当NameNode收到文件读写的请求后,会将请求定位到DataNode上,由DataNode直接和发送请求的节点交换数据,从而减少NameNode的工作负担。在HDFS系统中,Hadoop处理大文件的效率要高于处理多个小文件的效率[3],且编目系统是多以天为单位生成节目单的。因此,编目系统可以以天为单位,将12个录像文件的关键帧合成一个大文件,存储在HDFS上。HDFS默认文件分块大小是64MB。为了让每个DataNode都能保存完整的帧(即关键帧文件每64MB中,都包含整数个关键帧),从而在MapReduce分布式计算中,减少不同节点的通信量,可以对文件进行如下处理:
- 提取录像文件的关键帧,令当前关键帧的大小为L,当前处理的数据块的序号为K,对应的大小为N;
- 计算L+N的大小,如果L+N?64MB,则将当前关键帧直接填入到该数据块里,转入步骤1;
- 如果L+N>64MB,则将数据块k的剩余64MB-N的空间填充上0,并生成数据块K+1,将当前关键帧填入到数据块K+1中,再转入步骤1。
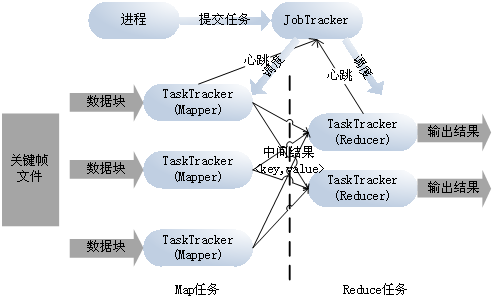
3.2 基于MapReduce的计算设计MapReduce计算结构中包括JobTracker和TaskTracker两类节点,分别用于调度任务和执行任务。其中,TaskTracker与HDFS的DataNode可以配置到同一个节点上,这样MapReduce在计算中,会自动优先处理本地存储的文件数据块,提高系统的处理效率。当系统检测到一个关键帧文件生成后,就可以调用MapReduce对文件进行分布式处理,计算结构如图3所示。
图3:计算结构
计算的步骤为:
- 系统向JobTracker节点提交视频处理请求;
- JobTracker为当前任务分配任务ID,将任务放到队列里等待其它任务执行完成;
- TaskTracker向JobTracker周期性的发送心跳信息,心跳信息包括本地任务的执行情况、以及当前可处理的Map和Reduce的任务数量。
- 在任务启动后,JobTracker可按照先入先出、公平、容量等调度算法调度TaskTracker[8]。
- Mapper节点对本地的关键帧逐个执行Map任务,生成键值对<日期,块序号+帧序号+处理结果>,将键值对发送给Reducer节点。
- Reducer节点会收到同一日期下所有关键帧的处理结果,在Reduce任务中会调用视频处理算法对结果进行合并,生成最终结果。
- 在TaskTracker执行任务时,一旦执行失败,JobTracker会将任务转移到其它节点继续执行。
在上述步骤中,Reducer节点需要收到所有Mapper执行结果后,才能对结果进行合并。因此,执行完成时间取决于受限于执行速度最慢的TaskTracker节点。为改善系统的计算效率,可以在MapReduce的配置文件中,开启speculative execution选项,在多个节点上同时执行相同的Map任务,这样Reducer节点就可以处理执行速度最快的Mapper节点的结果[9]。然而,这种操作有时会导致服务器过载,因此需要在执行速率和可靠性上取得一个平衡。
3.3 可靠性保证Hadoop的存储和计算结构中,NameNode和JobTracker都存在单点故障。一旦NameNode和JobTracker出现故障,则存储和计算都将不可用。因此,可以对上述设计进行改进:
- 依据计算任务类型和频道,将系统划分为多个Hadoop集群,每一个Hadoop集群都尽量独立处理相应的计算任务,减少不同Hadoop集群的交互。这样可以减少NameNode和JobTracker的负担,一旦某一个NameNode和JobTracker出现问题,不影响其它集群的工作。
- 在多个Hadoop集群的NameNode和JobTracker节点之间,搭建虚拟化资源池(如采用VMWare vSphere)[10]。NameNode和JobTracker都运行在虚拟机上,虚拟机文件则保存在共享存储中,一旦其中一个节点发生故障,可以迅速的将系统切换到另一个节点上。此外,还可以对虚拟机定期做快照备份,一旦当前的虚拟机出现损坏,可以将系统状态还原到之前的时间点上。依据之前的系统设计, NameNode和JobTracker比DataNode和TaskTracker的IO操作要小得多,因此,将虚拟机部署在共享存储中不会对系统性能产生很大的影响。
4 基于Hadoop的系统实现
Hadoop框架由Java语言和Linux Shell脚本编写,运行在Linux操作系统上。Hadoop代码本身并没有处理视频文件的功能,因此,需要对Hadoop的Java源代码进行相应的扩充,以支持对视频文件的操作。下面给出该系统数据处理的主要实现方法。
4.1 守护进程可在NameNode或JobTracker上实现守护进程。守护进程依据用户的配置信息,自动从集中存储中导入录像文件;并在文件导入完成后,自动启动相应的计算任务。
4.2 文件导入为了从集中存储导入录像文件,首先需要在NameNode上挂载集中存储所在的文件目录,即在Linux Shell下执行:mount 集中存储路径本地的路径NameNode通过FsShell类的copyFromLocal()方法将外存储的文件拷贝到HDFS文件系统上,因此可以设计类VideoFsShell类继承FsShell类,并重载copyFromLocal()方法。其伪代码为:Class VideoFsShell extends FsShellMethod copyFromLocal生成空的关键帧文件while 当天的文件未到齐等待新文件的到达提取文件的关键帧依据3.1节的算法,将关键帧加入到关键帧文件中end while
4.3本地任务的拆分Hadoop在Mapper节点上对每一个要处理的数据块都会生成类RecordReader。RecordReader会对该数据块循环调用nextKeyValue()生成<key, value>键值对,作为Map任务的输入。因此,可以设计类FrameRecordReader继承RecordReader,并重载nextKeyValue()方法,其伪代码如下:Class FrameRecordReader extends RecordReaderkey←文件块对应的日期blockID ←文件块对应的序号frameID ← 0pos ← 0Method nextKeyValueIf 帧已经读完return falseelse在文件的当前位置pos中,读取帧的内容,并记录帧的长度len生成键值对<key, blockID+frameID+帧内容>frameID ← frameID + 1pos ← pos + lenreturn trueend if4.4 Map和Reduce过程Hadoop会针对每一个<key,value>键值对调用Map任务处理帧,可以设计Map的处理过程为:Class FrameMapper extends MapperMethod map从<key,value>键值对中读取帧的内容调用相应的算法处理帧生成处理结果<key, blockID+frameID+帧处理结果>Hadoop会将Map任务生成的中间结果,按照key值进行排序,确保相同key的<key,value>在一个Reducer节点上进行处理。在Reducer上,针对每一个key值都会调用reduce过程处理Mapper完成的结果。这样,Reducer节点可以对同一天内的所有关键帧进行处理,生成相应的结果。其伪代码为:Class FrameReducer extends ReducerMethod reduce从当前key的所有<key,value>读取帧处理结果调用相应的算法对当天的帧进行处理输出<key, 处理结果>
5 结论
随着广电统一监管平台的数据整合,广播电视节目编目系统面临着处理海量视频文件的需求。如何将大数据技术应用到编目系统中,提高系统处理海量数据的能力,是当前编目系统亟待解决的问题。本文提出了基于Hadoop的广播电视节目编目系统优化方案,将视频处理的任务分配到不同的节点并行处理。由于Hadoop是开源云平台,且屏蔽了并行计算底层的实现细节,因此系统开发人员能够更多的关注系统的业务需求,定制大数据编目系统。对基于Hadoop的编目系统的性能进行定量的分析,是我们下一步的研究方向。
参考文献[1] 王婧. 基于电视自动编目技术的广告监管自动化系统[C]. 中国新闻技术工作者联合会第六次会员代表大会. 中国贵州贵阳: 2014.[2] Kambatla K, Pathak A, Pucha H. Towards optimizing hadoop provisioning in the cloud: Proceedings of the 2009 conference on Hot topics in cloud computing[Z]. San Diego, California: USENIX Association, 2009.[3] White T. Hadoop: The definitive guide[M]. O'Reilly Media, Inc, 2012.[4] 沈奇威,杨帆. 分布式系统Hadoop平台的视频转码[J]. 计算机系统应用. 2011(11): 80-85.[5] 孙淑霞,张浩. Hadoop云计算平台在视频转码上的应用[J]. 电脑与电信. 2011(12): 36-37.[6] 王利锋. 基于Hadoop的云转码系统研究及性能优化[D]. 北京交通大学, 2014.[7] 许鲁,马一力,傅湘林. 存储与计算的分离[J]. 计算机研究与发展. 2005(03): 520-530.[8] 赵晓东,陈玉云,柳先辉. 基于Hadoop平台资源调度策略的研究[J]. 电脑知识与技术. 2012(19): 4687-4690.[9] Dean J, Ghemawat S. MapReduce: Simplified Data Processing on Large Clusters[J]. Commun. ACM. 2008, 51(1): 107-113.[10] 于京杰,马锡坤,杨国斌. 基于虚拟化的云计算数据中心整体解决方案[J]. 中国医疗设备. 2012(12): 62-64.
编辑:中国新闻技术工作者联合会

{kind=link}
{kind=link}
{kind=link}
评论 点击评论