基于Spark框架的文本主题特征提取与分类
史铭 张焰 陈立佳
(新华社技术局)
摘要:主题模型目前广泛应用于机器学习与自然语言分析等领域,该模型自动分析一系列未识别的文档,试图通过统计信息发现多个抽象主题。主题模型在新闻文本智能处理与推荐领域的应用前景十分广阔。本文首先从文档自动分类为出发点,介绍文本分析的一般流程。在此基础之上,介绍主题模型和基于LDA模型的文本主题特征提取原理。最后结合Spark大数据处理的内存迭代和分布式计算特性,实现了基于LDA模型的文本主题提取过程,并给出了在新闻文本数据集上的主题抽取与分类预测结果。关键词:主题模型 特征提取 LDA Spark 新闻文本处理1.引言
近些年来,大数据技术迅速发展。随着数据量的不断提升,以及计算场景需求的多样化,传统的离线处理计算框架正在逐步朝着实时、高并发、可多次迭代的方向演进。受益于大数据技术的发展,新闻出版领域的数据挖掘和机器学习应用的工程实现难度有所降低。中文新闻文本的主题提取与自动分类问题在新闻出版领域有重要的应用价值。本文从文档自动分类的任务和特点入手,引入主题模型和相应的算法设计。根据计算的内存迭代要求,选择Spark计算框架,进行主题提取与分类的工程实现。我们在搜狗中文分类语料库上进行了相关测试,处理效果达到了预期。2.文档自动分类
在新闻出版领域,为了方便对文章或素材进行归类与管理,我们通常会在实际操作中给一段文章或素材指定一个或多个类别或属性。传统的人工标注对于时间和精力的消耗是巨大的。文档自动分类是机器学习领域针对这一场景的典型应用。文档自动分类通过相应的分类器实现类别预测功能。当对一个新文档进行分类时,分类器通常为这个文档指定一个或多个类别标签,并根据算法策略给出分类标签的可信度。按照机器学习方式的不同,文档自动分类的实现大体上分为两类,监督学习和非监督学习。监督学习方法是在“以往的观察”之上建立模型,这种“以往的观察”被称为训练集。在做文档分类时,预先定义好文档类别,再人工为训练数据集中每个文档打上类别标记。建立了训练数据集之后,接着用此数据集训练一个分类器。其思想是:在训练完成后,这个分类器将能够预测任何一个给定文档的类别。非监督学习方式有所不同,它们不需要训练数据集。以文档分类来说,类别是事先未知的。非监督学习方式(如聚合和话题建模),可以在一批文档中自动发现相似文档并进行分组。实际应用中,分类器一般由三个部分构成:数据集,数据预处理,分类算法策略。数据集由足够数量的高质量文档构成,文档自动分类对于数据集的质量要求很高。数据的预处理包括中文分词、词项的权值修正等,主要目的是将数据集转化为便于进行机器学习的格式,同时为提高结果的精度而进行的特定场景修正。分类算法与策略根据相应的模型计算文档的特征,最终实现对文档的分类处理。3.LDA主题模型的原理与工作过程
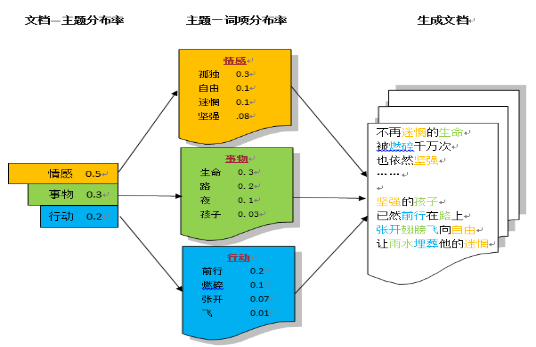
3.1主题模型根据维基百科的定义,主题模型(Topic Model)是在机器学习和自然语言处理等领域是用来在一系列文档中发现抽象主题的一种统计模型。直观来讲,如果一篇文章有一个中心思想,那么一些与中心思想词项关系密切的特定词项会更频繁的出现。举例来说,如果一篇文章是讲宠物狗的,那么“狗狗”和“骨头”等词出现的频率会高些。如果一篇文章是在讲宠物鱼的,那“鱼缸”和“鱼食”等词出现的频率会高些。然而,现实情况下文章通常包含多种主题,而且每个主题所占比例各不相同。因此,按照上述思想,如果一篇文章10%和主题A有关,90%和主题B有关,那么和主题B相关的关键字出现的次数大概会是和主题A相关的关键字出现次数的9倍。主题模型试图用数学框架来体现文档的这种特点,自动分析每个文档,并对文档内的词语进行统计,根据统计的信息来断定当前文档含有哪些主题,以及每个主题所占的比例各为多少。主题可以看作是语料集中词项的概率分布,主题模型通过词项在文档级的共现信息抽取出语义相关的主题集合,并能够将词项空间中的文档变换到主题空间,得到文档在低维度空间中的表达。主题模型训练推理的方法主要有两种,一种是PLSA(Probabilistic Latent Semantic Analysis),另一种是LDA(Latent Dirichlet Allocation)。PLSA主要使用的是EM(期望最大化)算法;LDA采用的是Gibbs sampling方法。任何模型或算法的落地,都需要为实际应用服务。主题模型可以用于如下几个方面:(1)文档主题分类与标注文档主题提取的结果直观体现了文档主题的分布。可以根据文档主题的分布结果,对文档的属性和关键信息提供必要标注。(2)文档主题降噪训练结果可以只保留最主要的分类主题,忽略次要主题,从而实现文档主题降噪。(3)文档语义相似性比对一篇文档的主题分布可以看作是对此文档的一个概率分布抽象表示,可以通过一些距离公式(如KL距离)来计算两篇文档的语义距离,从而得到它们之间的相似度。(4)确定多义词的特定场景含义同一个词语在不同的场景下,能表达不同的意义。通过求出来的“词语-主题”概率分布,就可以知道这个词语属于哪些主题,从而就可以通过主题的匹配来计算它与其它文字之间的相似度。此外,主体模型还有如下两个优点:(1)能够实现完全自动化的无监督学习训练过程中不需要引入人工标注,可以自动的进行以概率计算为基础的训练。(2)不受限于语言的形式任何经过分词处理后的语料都可以进行训练并得到主题分布。3.2 LDA模型的基本思想与算法潜在狄立克雷分配(Latent Dirichlet Allocation,LDA)模型是最简单的主题模型,它描述了一篇文章的产生过程。如图1所示:图1 LDA模型示意图
一个主题是由一些词项的分布定义的,每个主题由带有分布率的一系列词项构成。一篇文章则是由一些主题构成的,比如右边的直方图。具体产生过程是,从主题集合中按概率分布选取一些主题,从该主题中按概率分布选取一些词语,这些词语的无序集合构成了最终的文档。如果我们能将上述两个概率分布计算清楚,那么我们就得到了一个模型,该模型可以根据某篇文档推断出它的主题分布,即分类。由文档推断主题是文档生成过程的逆过程。LDA模型的数学原理比较复杂,其Gibbs Sampling公式如下:公式的右边部分其实就是doc—>topic—>word的路径概率,其物理意义其实就是在K条的路径上进行采样,K为topic的个数。对于文档分类的目标来说,LDA的过程分为两步:训练过程和推理过程。根据当前训练文档集,建立模型,这一步可以称为训练过程。在这一过程中,伴随着各种估计参数的方法,以实现模型建立和选最优。训练过程结束后,模型建立和参数优化已经完成。对新来的文档,根据目前的模型与参数,计算这个文档的topic分布。这一步可以称为推理过程。3.2.1训练过程算法 1 LDA 训练1:随机初始化:对语料中每篇文档中的每个词w,随机的赋一个topic编号z;2:重新扫描语料库,对每个词w,按照Gibbs Sampling公式重新采样它的topic,在语料中进行更新;3:重复以上语料库的重新采样过程直至Gibbs Sampling收敛;4:统计语料库的topic-word共现频率矩阵,该矩阵就是LDA的模型。3.2.2推理过程训练过程结束后,得到了参数doc-topic分布矩阵Θ和topic-word分布矩阵Φ。第一个doc-topic分布矩阵Θ由于在推理过程中并不起什么作用,在工程上一般不进行保存。然而,当训练过程的目的就是为了对已有文档进行处理时,也可以保存并使用。第二个topic-word分布矩阵Φ在推理的时候需要用到。来了一个新文档后,根据Gibbs Sampling公式为每个词的topic进行抽样,最终稳定后就得到了这篇文档的topic分布θ_new,同时在利用公式计算条件概率的时候,公式中的φ 保持不变。算法 2 LDA 推理1:随机初始化:对语料中每篇文档中的每个词w,随机的赋一个topic编号z;2:重复扫描当前文档,按照Gibbs Sampling公式,对于每个词w,重新采样它的topic;3:重复以上过程直至Gibbs Sampling收敛;4:统计文档中的topic分布,该分布即为所求的主体分布θ_new。- 选择Spark框架进行LDA模型训练
图2 Spark框架示意图
Spark适合于迭代运算比较多的机器学习与数据挖掘算法。其基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。处理过程中需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小。基于上述原因,我们选择在Spark框架下实现基于LDA模型的文档主题分类特征提取。5.基于Spark的LDA文本分类算法的实现过程
5.1 Spark分布式集群环境的搭建本次搭建的Spark分布式集群共有4个节点,其中一台作为master节点,三台为worker节点。安装过程本文限于篇幅不在赘述,软硬件配置参见下表。表1 Spark集群环境配置表
| 节点计算资源 | 2-vCores,8GB-Memory,40GB-Disk |
| 操作系统 | CentOS 6.3 |
| Java版本 | jdk1.6.0_38 |
| Scala版本 | 2.10.4 |
| Hadoop版本 | 2.6.0 |
| Spark版本 | 1.3.1 |
图3 分类训练结果
可以看到训练结果中各个主题与主题下的词项之间关联性显著,并具备一定的现实意义。例如Topic5应该描述的主题为美日军事发展相关内容。5.4.2推理过程任意选取一篇新的测试文本,执行推理过程,最后得到该文本所属的主题分布,并选取分布率最大的主题作为分类结果。如下内容的新文本,推理结果为Topic5。图4 测试文本示意图

{kind=link}
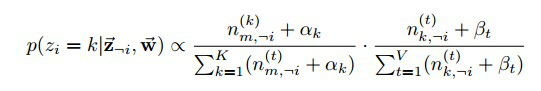{kind=link}
{kind=link}
{kind=link}
{kind=link}
评论 点击评论